controller是kubernetes中非常重要的角色,控制器负责协调不同的状态,相当于大脑的角色。在使用kubernetes的过程 或者在扩展kubernetes做其他开发中基本上都会用到。因此在这里记录下。
大纲
初识 Controller
Controller 与核心资源
Controller 和自定义资源custom resources
Controller的组件
Controller 事件流&基本工作机制
初识 Controller - Controller是什么🐎
Controller即控制器⚙️,在入门k8s时候想象大家都会接触到kubernetes组件结构图,里面有提到controller-manager, controller-manager是一个核心组件,相当于kubernetes的大脑🧠。它是个合集,有N多个小controller组成。
下载kubernetes源码,在目录kubernetes/pkg/controller可以看到以下多种控制器

从逻辑角度,controller分成很多,replication controller, endpoints controller, namespace controller, serviceaccounts controller,pv controller,甚至可以是youxxx controller ... ,从名字就能确定它所负责的模块。
从设计角度,controller又可以分成两类,原生controller和自定义 controller。所谓原生controller即Kubernetes内置的控制器,主要用于对内置原生资源的控制和处理,比如监听deployment资对象,然后调度,如何控制副本数量等等工作,这些是在deployment controller内完成。而另外一类自定义controller是个非常有意思的控制器,叫自定义控制器,也就是说,开发者是可以根据自己的需要来实现一个类似的
在Kubernetes里,controller 的职责是负责一个控制循环♻️,它通过API Server监听着集群的状态,并进行协调,总是尽可能地将当前集群的状态转变成期望的工作状态。
Controller 和自定义资源custom resources 📝
所谓自定义,就是它是开发者自行开发拓展的控制器,它的逻辑类似原生的控制器,做着类似的事情,但是它监听的对象很可能并不是原生的k8s资源,而且某一种"自定义的资源"。何为自定义的资源, 在k8s内,有一非常强大的拓展法宝-CRD(CustomResourceDefinitions),它允许开发者在 Kubernetes 里添加一个新的 API 对象,假设你有个外部系统,那么通过CRD,就可以将它集成到Kubernetes中,然后管理起来。
举个例子🌰,我有一个外部的系统资源称之为访问路径(accessPath)你不需要知道这个是什么,只需要知道它是一种资源,那么通过Kubernetes的CRD,进行定义并且应用后,那么我就可以用下面的yaml来创建一个叫访问路径的API 对象。这就是自定义资源。
apiVersion: "here2say.com/v1"
kind: AccessPath
metadata:
name: myap #object name in kubernetes
spec:
name: myap #name in SDS
type: Kubernetes #one of Kubernetes,iSCSI
cluster_info:
xmsServers: 10.252.90.39
secret_namespace: default
secret_name: xmssecret
gateway: vm39,vm40,vm41 #separated by comma,
🙋♂️然后就有人问,那controller和operator有什么关系吗 Operator也是使用了Kubernetes的自定义资源扩展API机制,使用CRD(CustomResourceDefinition)来创建。Operator通过这种机制来创建、配置和管理应用程序。controller + CRD + others => Operator 。 至少目前大多数的Operator都是这种模式。
Controller的组件
update: 发现了已有人画了一个不错的图
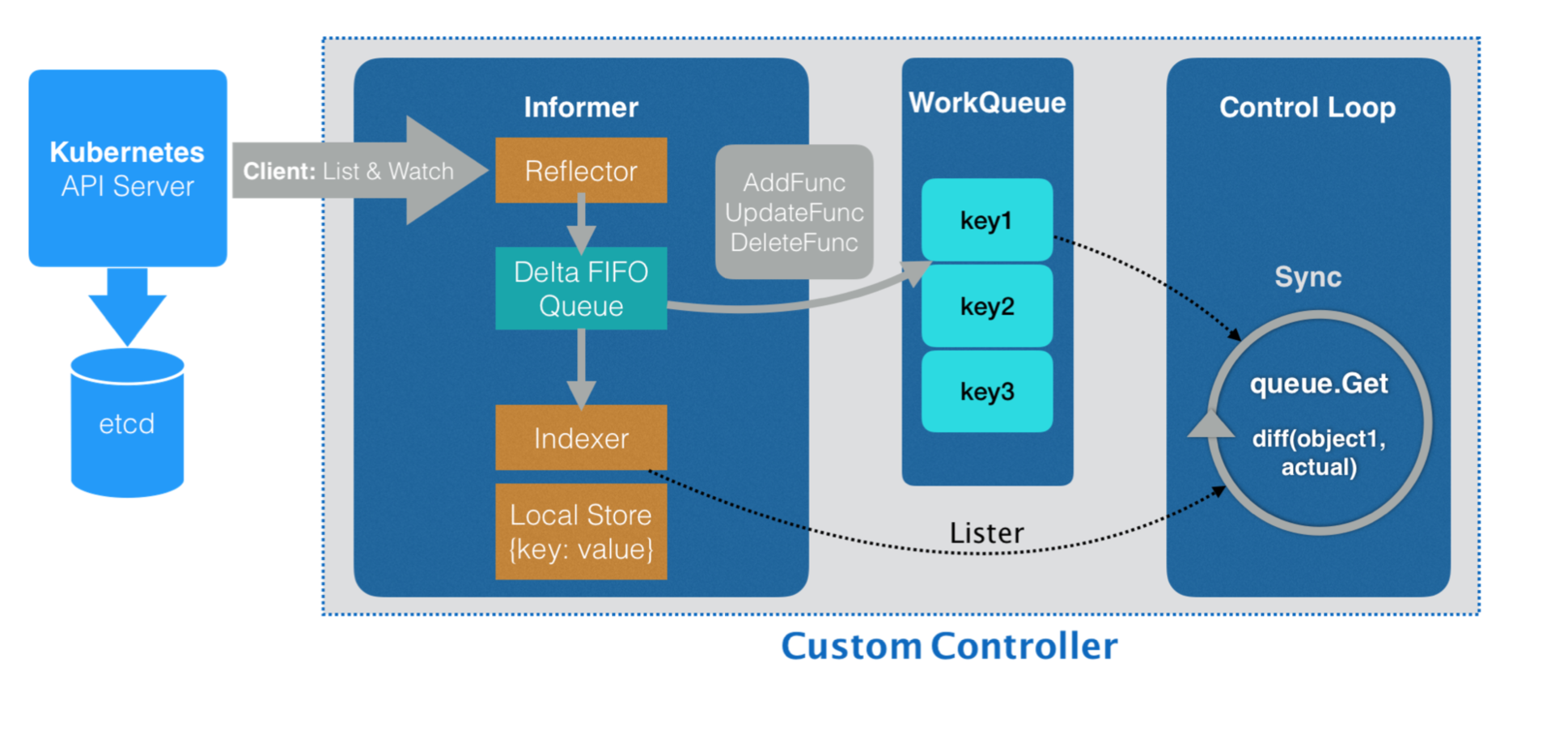
via 张磊
Informer
前面提到,controller 负责一个控制循环,它通过API Server监听着集群的状态(etcd),由于资源监听是实时的,如果每时每刻都向API Server发起请求查询,那么系统必然是压力山大的🍐。
考虑到这点,client-go包实现了一种缓存机制。同样它会查询API Server获取集群状态,但是并不是每次都直接查询,而是把查询结果缓存下来,并定期进行同步,这样来大大降低系统压力。
可以理解informer为一个监听器或者桥梁的作用,用于API Server和Controller之间,当API Server侧发生了状态的改变或者API 对象改变,informer会更新,并触发相应的回调事件。Infomer监听的事件包括:Add, Update,Delete.
你可以通过client-go包得到一个API 对象的informer 下面是kubernetes官方给出的一个例子,使用deploymentInformer注册监听deployment的新增,更新和删除事件,在这个例子,当k8s集群新增一个deployment,那么就会触发到回调函数controller.handleObject进行相应的处理:
deploymentInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleObject,
UpdateFunc: func(old, new interface{}) {
newDepl := new.(*appsv1.Deployment)
oldDepl := old.(*appsv1.Deployment)
if newDepl.ResourceVersion == oldDepl.ResourceVersion {
// Periodic resync will send update events for all known Deployments.
// Two different versions of the same Deployment will always have different RVs.
return
}
controller.handleObject(new)
},
DeleteFunc: controller.handleObject,
})
so far so good
机智的你一定想到了,我们知道有这么多的对象,那就有可能定义了很多的informer了,有podInformer,deploymentInformer..而且可能到处都有 同样是PodInformer,你觉得需要用到就写了一个,隔壁老王也搞了一个podInformer。 为了解决这种情况,于是有了SharedInformer, SharedInformer是能在不同的controller中共享的一个缓存实例。也就是说在上游对接API Server的是只有同一个生产者,而你和老王都是消费者,大家都通过AddEventHandler注册自己的处理函数,来消费API Server某个对象的Add, Update,Delete 事件,然后在各自的controller中进行状态协调。
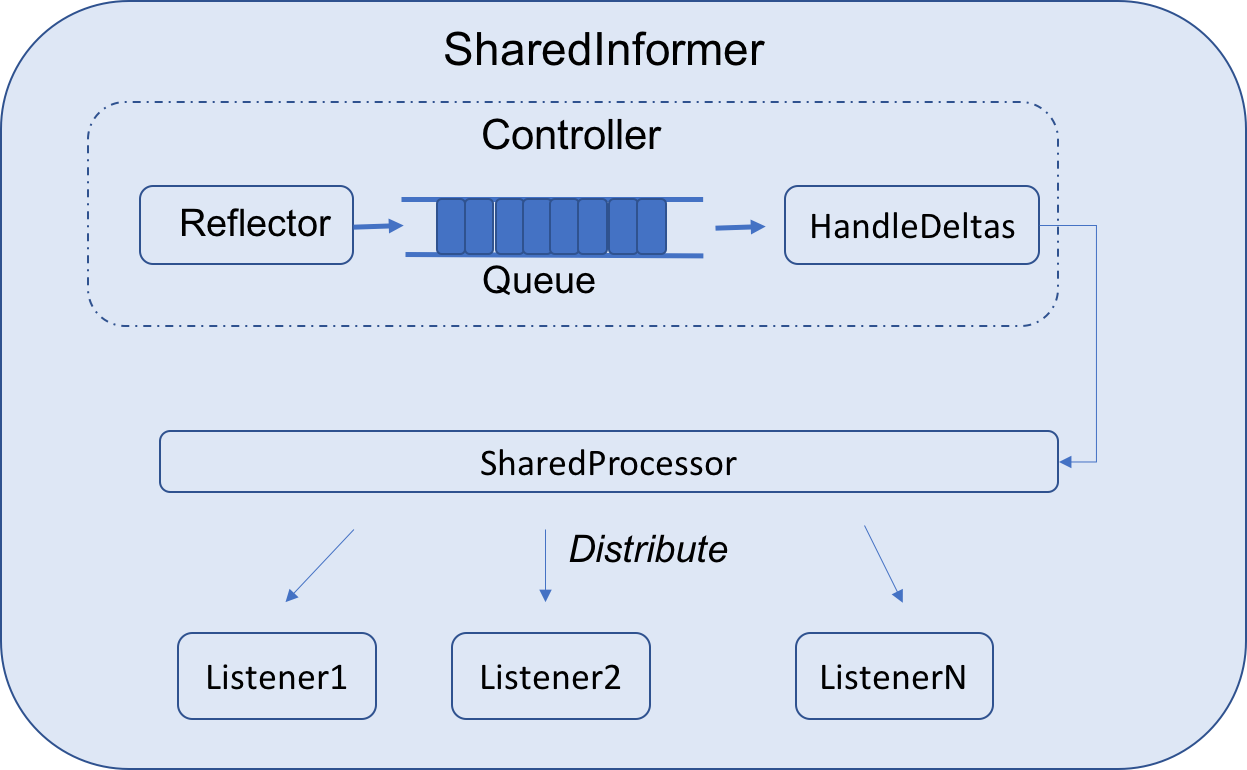
one more questions🤔
既然以producer-consumer的模式的化,那一个SharedInformer监听到一个API 对象的变动并通知了Controller的处理函数后,它理应就不管订阅者们的执行情况了,因为它是共享型的,并不管后面哪个controller消费这个事件,因此,需要有controller有自己的队列管理机制。也就是上图的Queue部分。
Workqueue
大多数的Controller通过Informer知道有变更事件的时候,都是先把这个对象存放在一个队列中(通常是resource_namespace/resource_name 的格式),然后后台的worker取出对象进行处理的一种解耦模式。然后worker根据执行情况决定是否重新入队。
client-go包已经有了这种实现(client-go/util/workqueue)。比较常见的有rate limiting queue。
eg:
queue :=
workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
这是一种带有频率限制的队列机制,工作流程参考别人做的图
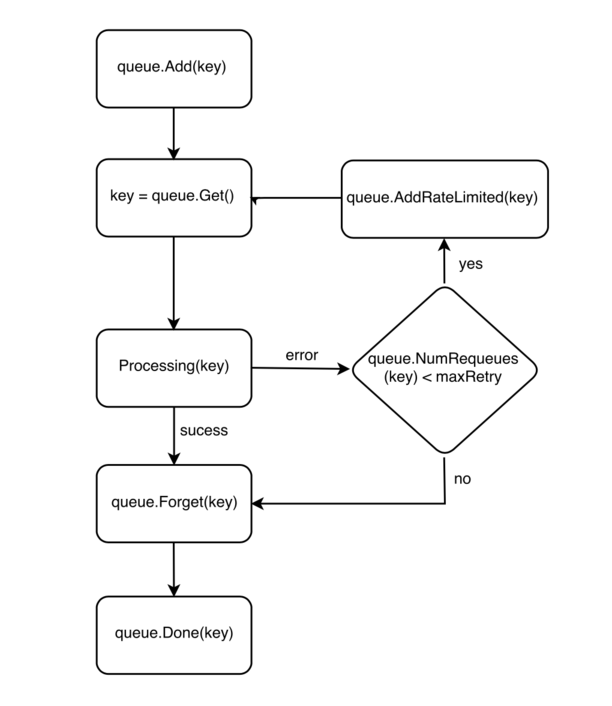
Controller 基本工作机制 - 事件流
在Kubernetes里,controller 的职责是负责一个控制循环♻️,它通过API Server监听着集群的状态,并进行协调,总是尽可能地将当前集群的状态转变成期望的工作状态。
用伪码表示如下:
for {
desired := getDesiredState()
current := getCurrentState()
makeChanges(desired, current)
}
如果从全局来看: 下图包括了custom resource, 属于kubernetes集群中的资源,它像内置的资源对象一样,都是一等公民 最终这些资源持久化保存在etcd中。作为API中心的API Sever则负责将存储后端管理起来。 作为控制中心的controller通过和API Server沟通获取集群的状态。并操作如何动态调整实际状态。
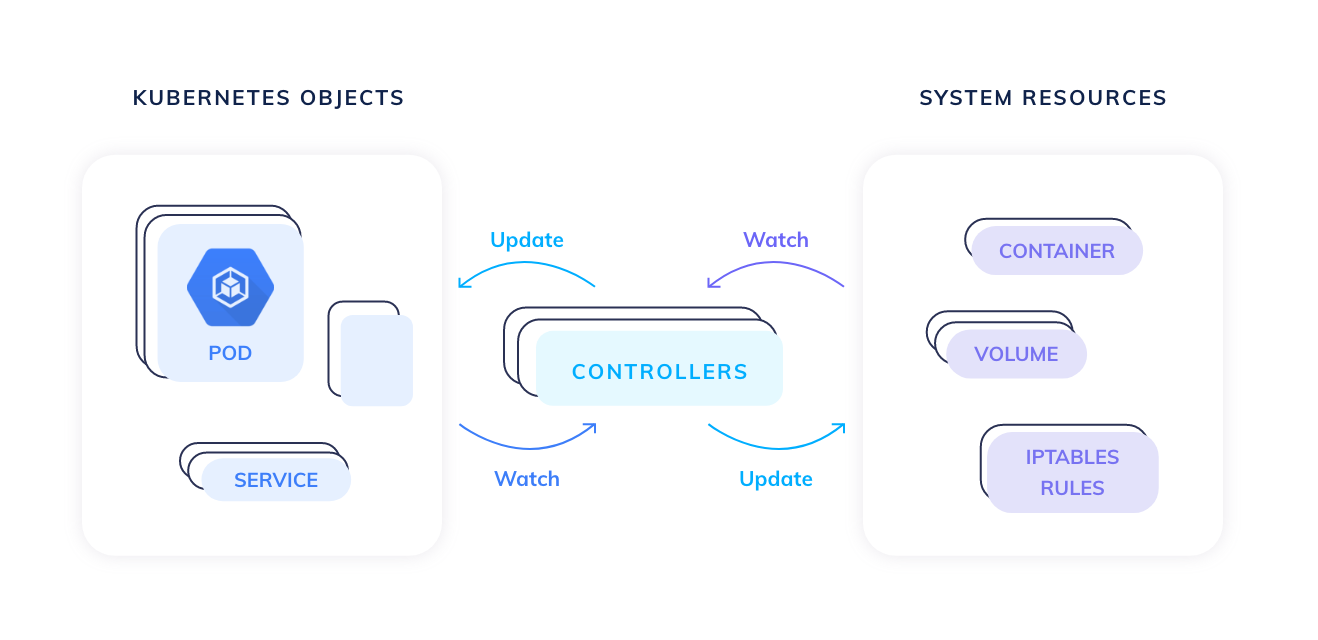
上图是总览,没提现细节,那么下图就是一个放大视角
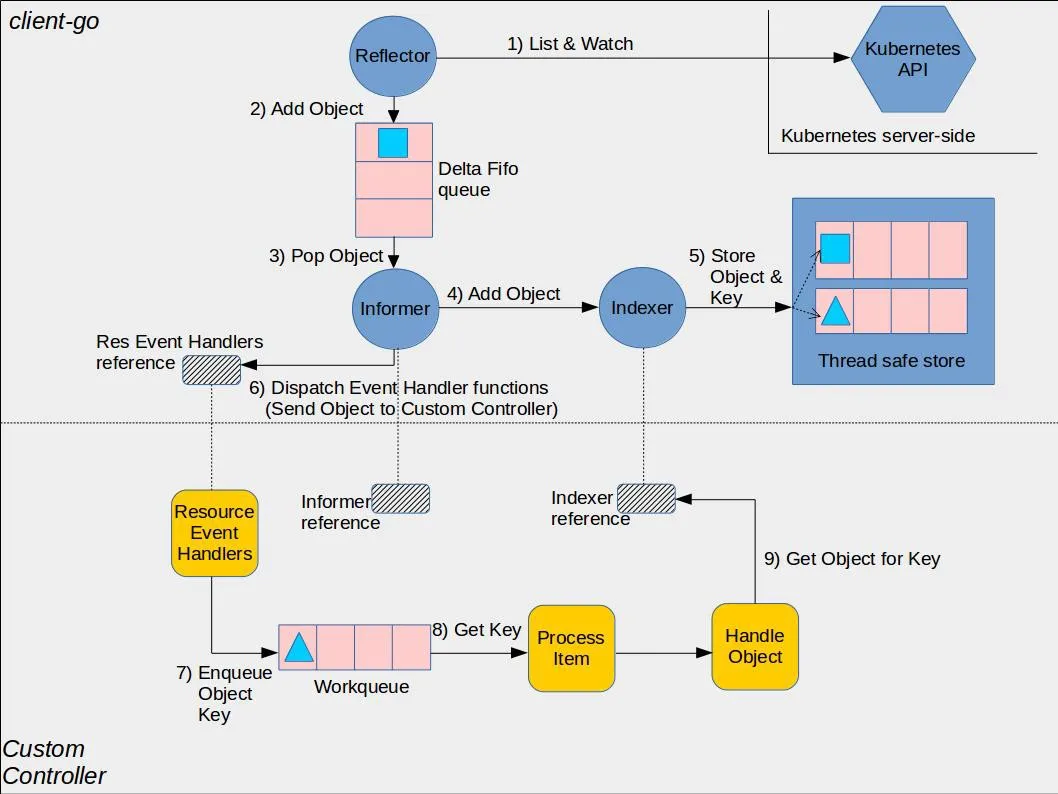 可以看到controller是通过informer间接地观察到API Server的变化。
每个变动(新增,更新或者删除)此资源就被添加到WorkQueue,从而被controller消费。
可以看到controller是通过informer间接地观察到API Server的变化。
每个变动(新增,更新或者删除)此资源就被添加到WorkQueue,从而被controller消费。
总结:
本篇介绍了什么是controller, Controller是干什么的。 controller的分类和区别,于是引出custom controller和custom resource和crd 然后也介绍了Controller最基本的组件 informer和workqueue,他们后续写自定义控制器必不可少的部分。 最后也用提示说明了Controller的工作原理 这篇有很多都是基础介绍,主要是为了后面的铺垫,时间允许的话,后续会就此继续深入, 或者一步一步演示如何拓展kubernetes编写自己的控制器或Operator。