很早就想写这篇文章,毕竟已经基于Kubernetes开发有一段时间了,需要做一个阶段性总结。 按照大纲,将会有三篇, 其中第一篇为基础篇章,主要讲解kubernetes中的存储概念以及基本使用 第二遍为中级篇章,只要结合源码讲解kubernetes存储细节以及流程 第三篇为深入csi,手把手教学任意存储厂商编写驱动教程
本篇作为基础会把kubernetes涉及的存储概念交待清楚并配以实战.
需求导入
早期在docker的设计中,容器是无状态的,随时使用随时销毁,基本上是设计给无状态的应用程序使用,随着容器编排系统的发展,容器应用场景日渐复杂,有状态服务的需求日益明显,因此寻求容器平台的存储解决方案是一件大事.
早期的容器存储
在docker上有一种存储概念叫volume,但是这种volume比较简单,基本上就是宿主机上一块简单存储路径, 如果有使用过Docker经验的话,就会发现在Docker中就有Volume的概念,Volume本质上是容器上挂载的某个目录 [1]。
Volume(卷)
Kubernetes同样也有Volume的概念,它属于Pod内部共享资源存储,生命周期和Pod相同,与Container无关,即使Pod上的容器停止或者重启,Volume不会受到影响,但是如果Pod终止,那么这个Volume的生命周期也将结束。
Persistent Volume(持久卷)
显然,这样的存储无法满足有状态服务的需求,于是有个Persistent Volume(PV)即持久卷,故名思义,持久卷是能将数据进行持久化存储的一种资源对象。PV,它是独立于Pod的一种资源,是一种网络存储,它的生命周期和Pod无关。云原生的时代,PV的种类也包括很多,iSCSI,RBD,NFS,以及CSI, CephFS, OpenSDS, Glusterfs, Cinder等网络存储。可以看出,在kubernetes中支持的持久卷基本上都是网络存储。只是支持的类型不同
对比

可以看出Volume和Persistent Volume的最大区别是生命周期,PV是一种独立的存储,管理员只需要在存储上创建足够的PV就可以提供给计算节点中的Pod来使用,而且数据是持久存储
用通俗的语言解释就是PV是kubernetes内的存储资源,具体类型会很很多种类,不管是哪一类,PV代表的就是某种存储,
参考以下表格,这是从官方文档看到的PV支持情况 Kubernetes supports several types of Volumes:
awsElasticBlockStore,亚马逊云存储 azureDisk,微软azure云存储(块) azureFile,微软azure云存储(文件) cephfs, ceph文件存储 cinder configMap,基于kubernetes的etcd组件实现的原生存储 csi 通用容器存储接口 downwardAPI 下行API emptyDir fc (fibre channel) flexVolume flocker gcePersistentDisk gitRepo (deprecated) glusterfs hostPath iscsi local nfs persistentVolumeClaim projected portworxVolume quobyte rbd scaleIO secret storageos vsphereVolume We welcome additional contributions.
其中需要注意的几个类型: csi类型: csi类的PV表示某一类存储,可以通过容器存储接口对其进行访问和控制,这里说的容器存储接口是k8s社区定义的一些rpc接口,k8s会通过gRPC和存储提供商的驱动进行通信来实现csi卷的操作,比如创建PV,则会通过gRPC发送CreateVolume请求到驱动端。
hostpath: 严格来说,hostpath并不算网络存储,它代表的是宿主机上的文件或者文件夹甚至可以是块设备,UNIX socket,其本质是属于宿主机的文件系统。常用于挂载宿主机的一些工具或者公共使用目录
PVC类型(persistentVolumeClaim): PVC更特殊,它甚至都不算具体的存储。它这是个声明,实际上它会隐藏后段存储细节,只能知道它是代表了某一类存储,是一种抽象资源。PVC是用来挂载到Pod的存储,Pod不需要知道具体的后端存储实现(它不关注这到底是rbd还是iscsi还是其他,对于pod而言它知道这是一段存储资源),因此它可以直接就使用PVC这个虚拟的存储(实际使用的时候这个抽象存储会关联具体的PV)。
downwardAPI: 这个也比较特殊,当我们的pod需要k8s集群的一些信息的时候,它可以通过挂载一些特殊的目录进来然后读取他们得到所需要的API值。比如某个pod想要获取宿主机上的node ip,k8s就可以通过这个挂载downwardAPI volume到pod内,pod就可以知道它要的node ip了。
怎么使用
这里简单演示下如何在Pod中使用PVC,PV,并且存储类型选择为iscsi。 iSCSI是一种网络存储,就透过TCP传递SCSI指令,用于提供块存储服务。
关于iSCSI 服务不细,超出本文范围,但简单概括下:
iSCSI initiator:在计算机与存储装置关连中,你的计算机被称为“iSCSI initiator”(iSCSI启动器),因为它开启链接至存储装置。
iSCSI Target:它概念类似于一种联机接口,当iSCSI启动器联机至iSCSI Target时,iSCSI Target上连结的所有LUN也会联机至客户端的操作系统。
iSCSI LUN:在iSCSI环境中的LUN实际上就是经过编号的硬盘或是实体硬盘所建立的一个储存空间,它是真正的存储实体。用户可以在这些iSCSI LUN上建立并管理文件,就像管理本地硬盘一样。
准备工作
首选要有个可用的iscsi服务 目前东家是做软件定义存储的,我就用SDS创建一个iSCSI服务: 假设如下: targetPortal: 10.252.90.44:3260
iqn: iqn.2018-09.vm44.17:1eb033f6fa43afd3
lun: 0
使用方法一:直接使用volume(不推荐)
编写yaml定义,直接在Pod内绑定一个iscsi volume 定义pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: iscsi-vol-pod
spec:
containers:
- name: iscsi
image: kubernetes/pause
volumeMounts:
- mountPath: "/mnt/iscsipd"
name: iscsi-vol
volumes:
- name: iscsi-vol
iscsi:
targetPortal: 10.252.90.44:3260
iqn: iqn.2018-09.vm44.17:1eb033f6fa43afd3
lun: 0
fsType: ext4
readOnly: true
可以看到Pod是直接直接消费iscsi Volume的,Volume的配置类型为iscsi,填好相应的参数就行。
然后在kubenetes的master节点下执行
kubectl create -f pod.yaml
稍等一下查询状态:
kubectl get pod iscsi-vol-pod
kubectl describe pod iscsi-vol-pod
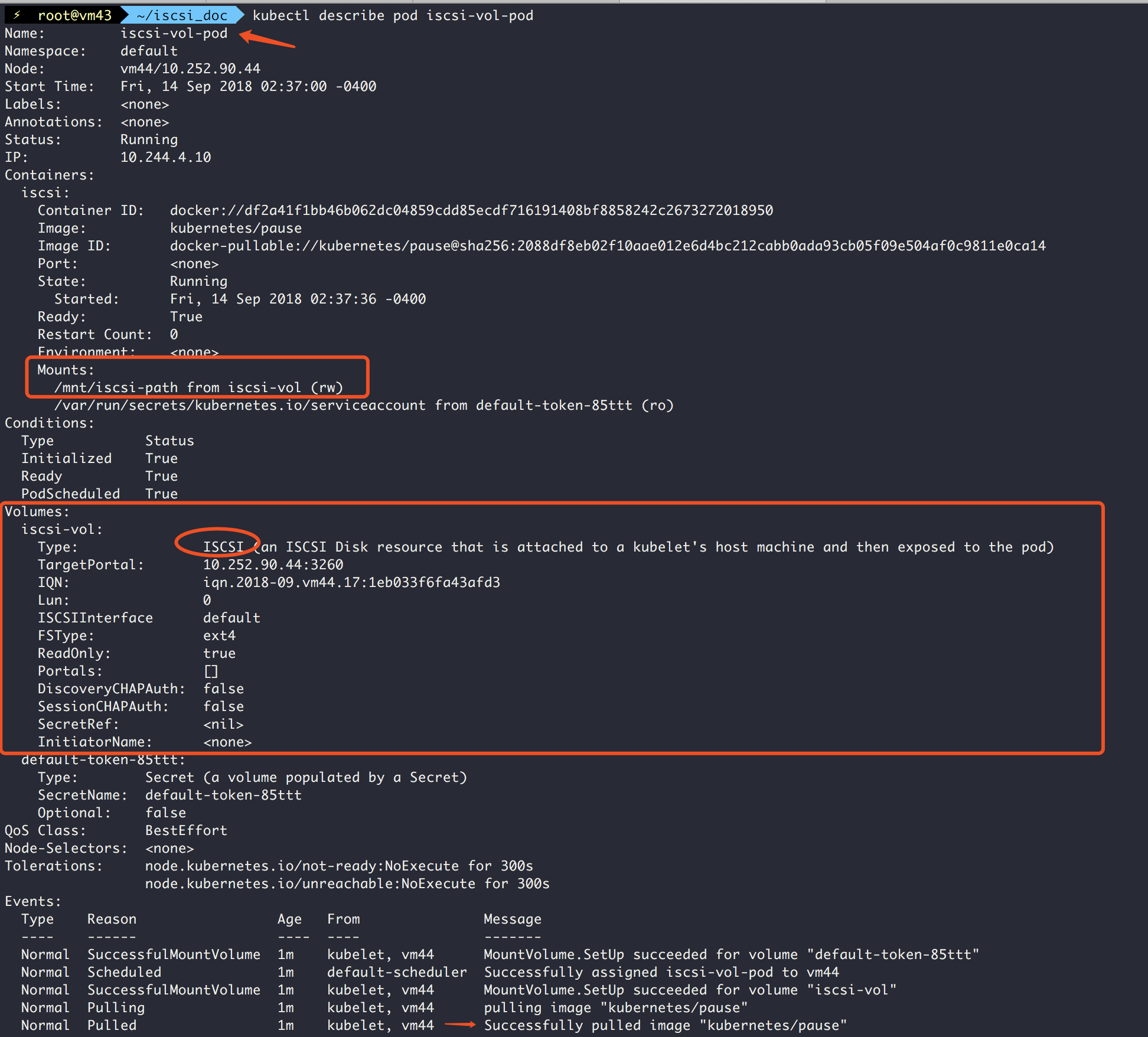
验证
看到pod起来之后
登陆到该pod所在的机器,这里是Node: vm44/10.252.90.44
查看卷:
df -h | grep iscsi-vol

测试2 使用PVC 方式 (推荐)
创建iSCSI的操作同上
定义pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: iscsi-pvc-allin1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
执行:
kubectl create -f pvc.yaml
然后定义PV如下pv.yaml,注意填写相应的iSCSI配置:
apiVersion: v1
kind: PersistentVolume
metadata:
name: iscsi-pv-allin1
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 1Gi
iscsi:
targetPortal: 10.252.90.45:3260
iqn: iqn.2018-09.vm45.18:14509846200896b7
lun: 0
创建的iSCSI信息修改为你的配置targetPortal,iqn,lun,storage
然后在master节点创建
kubectl create -f pv.yaml
其中PVC的storage不可以大于PV的storage,否则Pod无法消费该卷 创建完成之后稍等一下,如无意外,刚创建的PV和PVC就会进行绑定 前面两步执行完就可以看到已经绑定好了
kubectl get pv,pvc
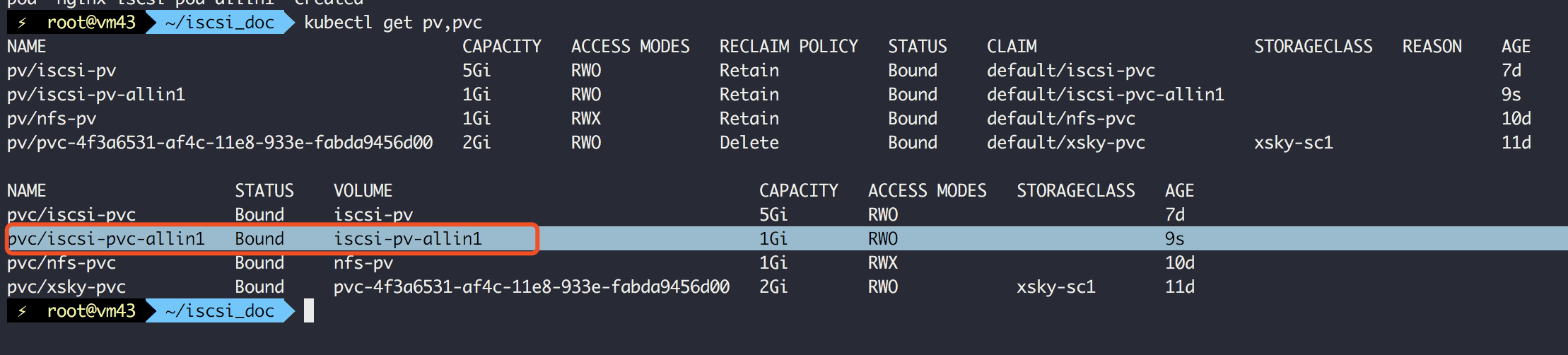
继续定义pod.yaml,消费刚才定义的PVC(注意,不是PV)
apiVersion: v1
kind: Pod
metadata:
name: nginx-iscsi-pod-allin1
labels:
name: nginx-iscsi-pod-allin1
spec:
containers:
- name: nginx-iscsi-pod-allin1
image: fedora/nginx
ports:
- name: web
containerPort: 80
volumeMounts:
- name: iscsivol-allin1
mountPath: /usr/share/nginx/html
volumes:
- name: iscsivol-allin1
persistentVolumeClaim:
claimName: iscsi-pvc-allin1
然后在master节点创建
kubectl create -f pod.yaml
这里是先创建PV,PV和PVC绑定,然后在Pod中引用此PVC进行消费的
即Pod--PVC--PV
创建成功后:
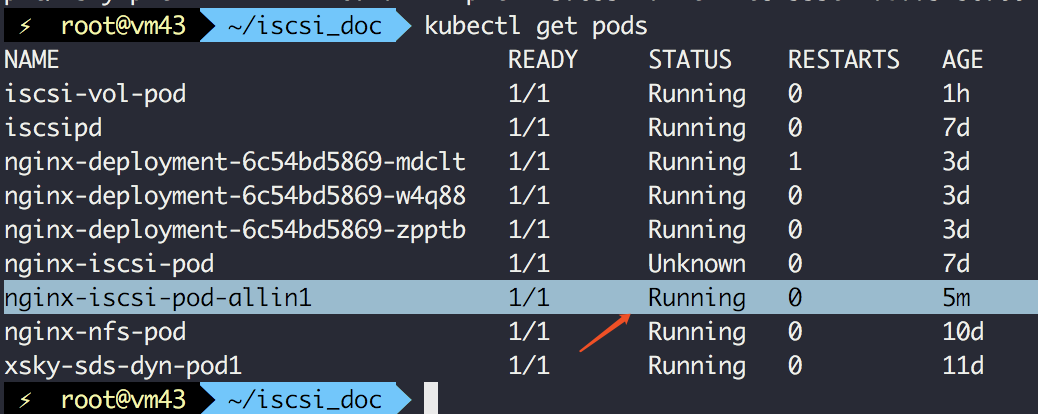
验证绑定
kubectl describe pod nginx-iscsi-pod-allin1

上面两个例子展示了如何在Kuberneres编排系统中使用持久化存储的示例,其中第一个例子仅供参考,不建议那样使用。 对于第二种,PV-PVC-Pod这种消费方式是一种常规的手段。 另外据我测试,在其他的编排系统比如open shift或者rancher也是可以这么操作的。
总结PV,PVC
Kubernetes对于有状态的容器应用或者对数据需要持久化的应用,不仅需要将容器内的目录挂载到宿主机的目录或者emptyDir临时存储卷,而且需要更加可靠的存储来保存应用产生的重要数据,以便容器应用在重建之后,仍然可以使用之前的数据。不过,存储资源和计算资源(CPU/内存)的管理方式完全不同。 为了能够屏蔽底层存储实现的细节,让用户方便使用,同时能让管理员方便管理,Kubernetes引入了PersistentVolume和PersistentVolumeClain两个资源对象来实现对存储的管理子系统
Persisten Volume (PV)是对底层网络存储的抽象,将共享存储定义为一种“资源”,比如节点(Node)也是一种容器应用可以“消费”的资源。PV由管理员进行创建和配置,它与共享存储的具体实现直接相关,例如GlusterFs、iSCSI、RBD或GCE/AWS公有云提供的共享存储,通过插件式的机制完成与共享存储的对接,以供应用访问和使用
PersistentVolumeClaim (PVC)则是用户对于存储资源的一个“申请”。就像Pod “消费” Node的资源是一样的,PVC会消费PV的资源。PVC可以申请特定的存储空间和访问模式。
使用PVC“申请”到一定的存储空间仍然不足以满足应用对于存储设备的各种需求。通常应用程序都会对存储设备的特性和性能有不同的要求,包括读写毒素、并发性能、数据冗余等更高的要求
Pod通过消费PVC,避免了直接在容器内定义后端存储,有一定程度松耦合。 但是缺点就是要求管理员提前在Kubernetes集群以及相应的存储平台创建大量PV。 当Pod需要只有存储资源的时候通过PVC进行选取这些预先创建的PV,然后绑定消费。
找到了一个不错的讲解图:
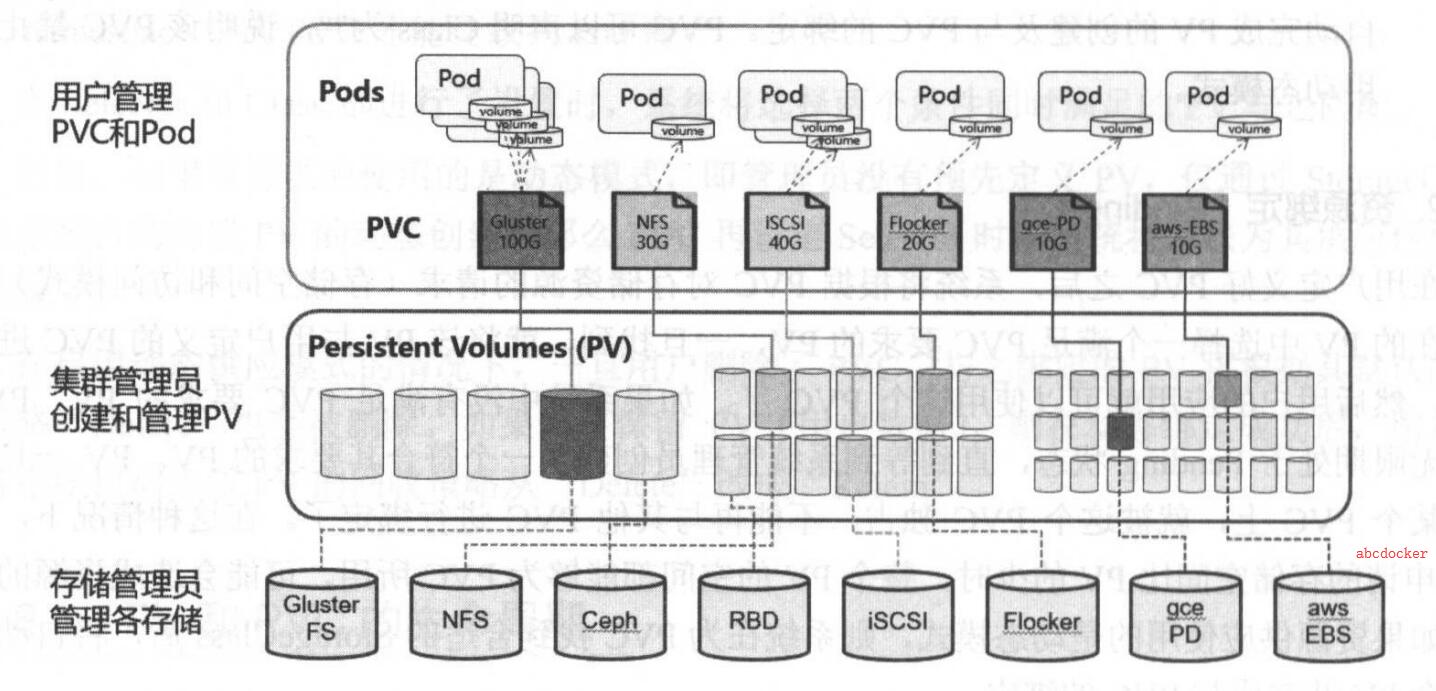 //参考源自https://docs.he-jason.com/
//参考源自https://docs.he-jason.com/
Kubbernetes存储供应方式
Kubernets支持两种资源的供应模式:
静态模式(Static)和动态(Dynamic),资源供应的结果就是创建好的PV。
静态供应
所谓静态供应就是管理员提前在Kubernetes集群以及相应的存储平台手动创建大量PV。等需要消费的时候直接从手动创建的PV进行消费。 比如上面的演示二就是这样的情况。
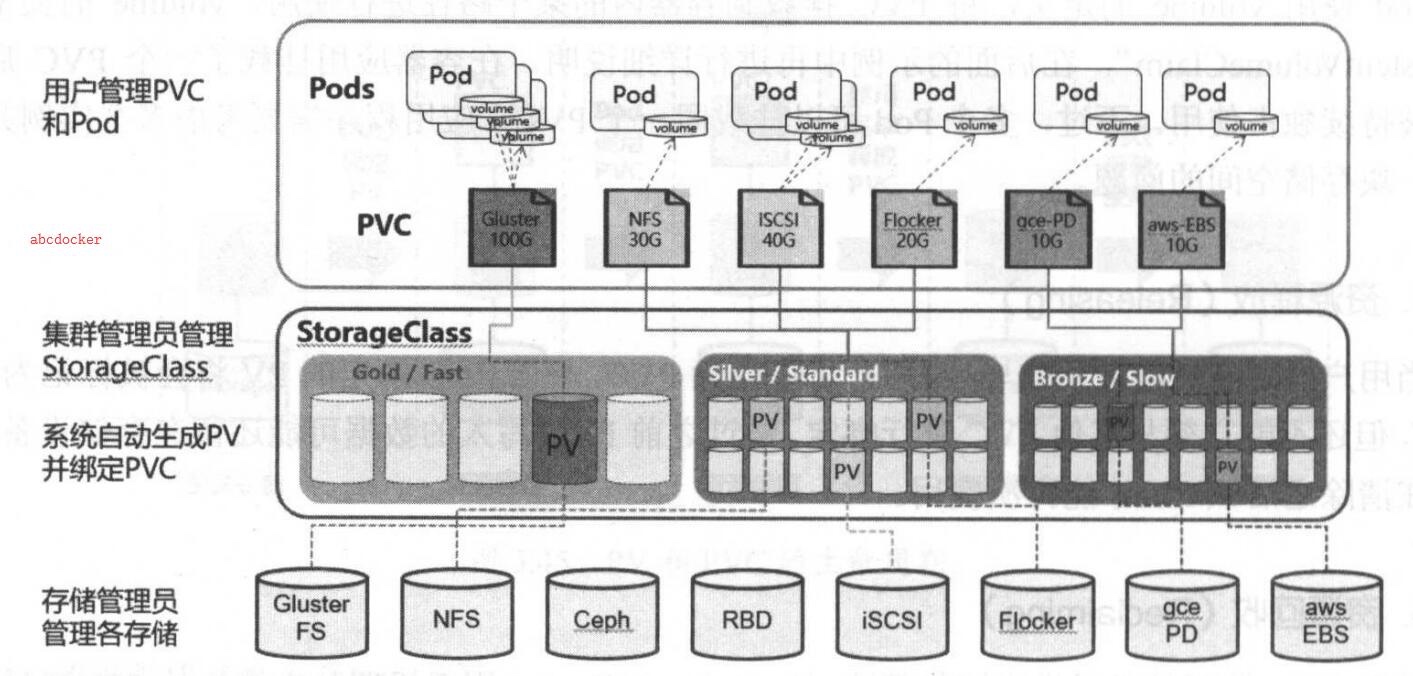
动态供应Dynamic Provisioning
iSCSI,RBD,NFS等PV分别代表了各种类型的存储资源,供集群消费,PersistentVolumeClaim(PVC)就是对这些存储资源的请求。PVC消耗的资源是PV,这很好理解,就像Pod消耗Node资源一样。于是,在Kubernetes中Pod可以不直接使用PV,而是通过PVC来使用PV。
通过PVC可以将Pod和PV解耦,Pod不需要知道确切的文件系统和支持它的持久化引擎,可以把PVC理解为存储的抽象,把底层存储细节给隔离了。另一方面,如果使用PV作为存储的话,需要集群管理员事先创建好这些PV,但是如果使用PVC的话则不需要提前准备好PV,而是通过StorageClass把存储资源定义好Kubernetes会在需要使用的时候动态创建,这种方式称为动态供应 (Dynamic Provisioning)。
那么什么是StorageClass(SC)
StorageClass翻译成中文就是存储类,用于标记存储资源的特性和性能。它类似存储池的概念,包括了存储池的一些信息。 因此可以理解为某一个类型的存储的定义类/或者说配置了的存储池。它能结合provisoner和pvc进行创建PV实现动态供应。
如图所示:
通过StorageClass和PVC完成资源动态绑定 (系统自动生成PV,并供Pod使用的存储管理机制)
todo
这里应该补一个动态供应的示例 迫于篇幅,没办法演示这么多,可以移步https://www.kubernetes.org.cn/4078.html查看动态供应的示例。 或者查看社区另一个动态供应nfs的demo: https://github.com/kubernetes-incubator/external-storage/tree/master/nfs-client#kubernetes-nfs-client-provisioner
动态供应详解
这是我总结的一个分析图
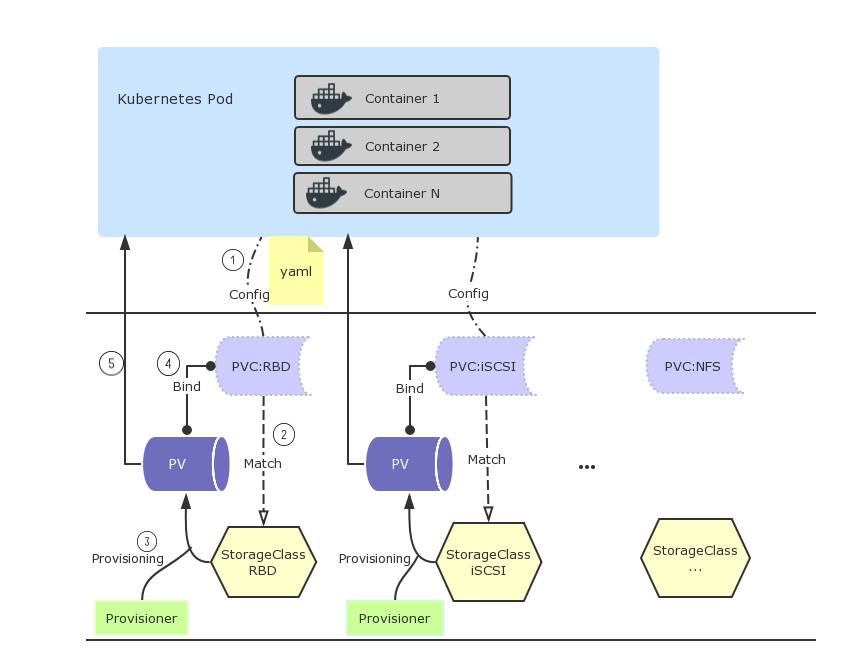
详细流程分析如下:
Pod加载存储卷,请求PVC
PVC根据存储类型(此处为rbd)找到存储类StorageClass
Provisioner根据StorageClass动态生成一个持久卷PV
持久卷PV和PVC最终形成绑定关系
持久卷PV开始提供给Pod使用
简单总结下,如果在Kubernetes中运行有状态服务,比如数据库MySQL,MongoDB或者中间件Redis,RabbitMQ等,那么就需要用持久卷(PV),从而不用担心随着Pod的终止而丢失数据(相比使用了普通Volume)。 另外,从以上对比可看出,直接使用PV适合变动较少,不会频繁修改的场景,是比较直接的使用方式。
面对计算层的多种存储需求,要考虑如何高效且灵活的提供存储服务于是就有了动态供应的策略。动态供应能按需分配资源,大大减轻了运维工作,是目前最为推荐的一种方式,在很多企业生产环境中都有它的应用。
如何实现动态供应
显然动态供应比静态供应灵活更多,而且这种方式还解耦了Kubernetes系统的计算层和存储层,更重要的是它给存储供应商提供了可插拔式的开发模型,存储供应商只需要根据这个模型开发相应的卷插件即可为Kubernetes提供存储服务。
有以下方法实现卷插件:
- In-tree Volume Plugin
- Out-of-tree Provisioner
- Out-of-tree CSI Driver
Kubernetes内部代码中实现了一些存储插件,用于支持一些主流网络存储,叫作In-tree Volume Plugin。
第二种 Out-of-tree Provisioner:如果官方的插件不能满足要求,存储供应商可以根据需要去定制或者优化存储插件并集成到Kubernetes系统。
第三种是容器存储接口CSI (Container Storage Interface),是Kubernetes对外开放的存储接口,实现这个接口即可集成到Kubernetes系统中。CSI特性在刚过去的12月正式GA,同时社区也宣布未来将不再对In tree/Out of tree继续开发,并将已有功能全部迁移到CSI上,所以对于存储供应商和使用者来说,第三种CSI是更推荐的解决方案。
写在最后
本来这章作为开篇,想简单点不写那么长的,结果还是这么长😅
概念实在太多,不知道从哪来精简,怕一精简就看不懂了😸
其实动态供应才是我们的目标,所以下次我们就专注于动态供应存储方案的实现。
ref: