Raft是分布式系统中常用的基于Paxos的Consensus算法。相比于Paxos,Raft设计采用了较少的状态,并且是一种更简单、更易于理解的算法。
目前有不少的应用都是采用raft协议来保证集群节点一致性,比如ectd,consul,以及当前我们在做的存储产品也是,
网上看了下,介绍有点啰嗦而且复杂化了,因此这里做个简单总结。
分布式系统需要考虑什么
首先思考下,如何从无到有的搭建一个分布式数据库(放心本文不涉及写代码环节,只是分析原理😂)
说到分布式,首先得有多个节点,多个节点间会相互通信,需要知道彼此的ip,或者用rpc的方法,有种方法检测彼此的心跳。
PAC中的第一个'Partition',就是分布式中绕不开的话题‘脑裂’。你需要想一个方法,让多个节点在网络分区的时候(例如交换机断开了等等)不会分头行动,每个节点都觉得自己是正确的,从而接收client的修改并提供服务,这就不好了。
接着上一条,你得考虑你的方法是要受限于奇数个节点吗?如果不要求节点个数,是否有别的努力要做。
在解决好P后,为了任务的简单,不要大家都跑一样的流程,可以提出单master的概念,即大多数逻辑都只跑在master上(单主并不low,大型如k8s都是单master的,如果有瓶颈可以再从功能上去拆分)。那么你得想一个法子去选举master并保证选举的有效性。
OK,选举出master后,那么可以用一个简单的流程,来控制ip的接管与释放,包括数据库的操作。
后续就要带着上面的问题。
分布式系统工作方式
单个节点
假设左边是一个客户端,右边是一个业务节点,比如一个数据库。

当只有一个节点的情况下,那是十分简单,直接请求就行
三个节点
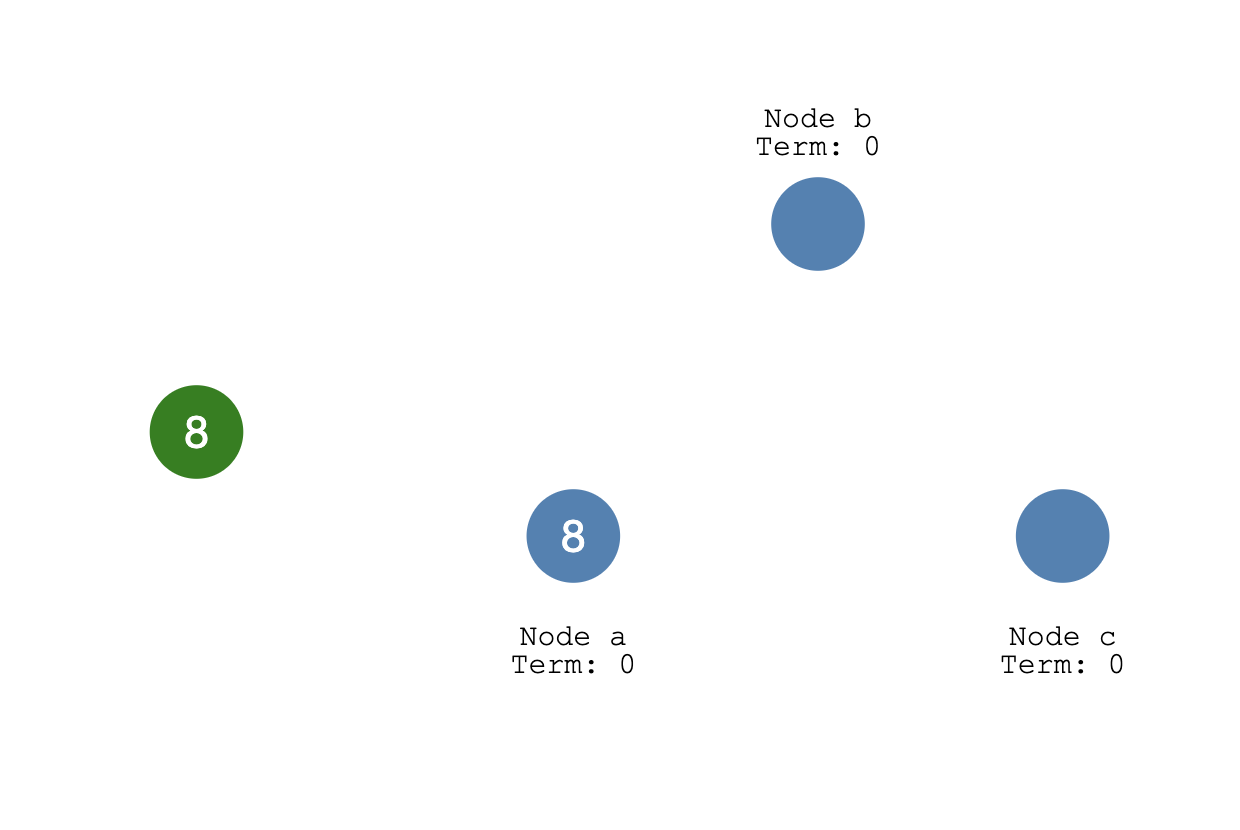
当有三个节点的系统(多个副本),那就要考虑分布式一致性 而Raft就是一种实现分布式一致性协议。 此时需要进行选举操作,结果就是产生一个leader角色,其他的当follower。(具体选举方式后面会说) 假设这里Node a被选为master
- 如果客户端发送了一个请求,要是设置一个值SET 5:
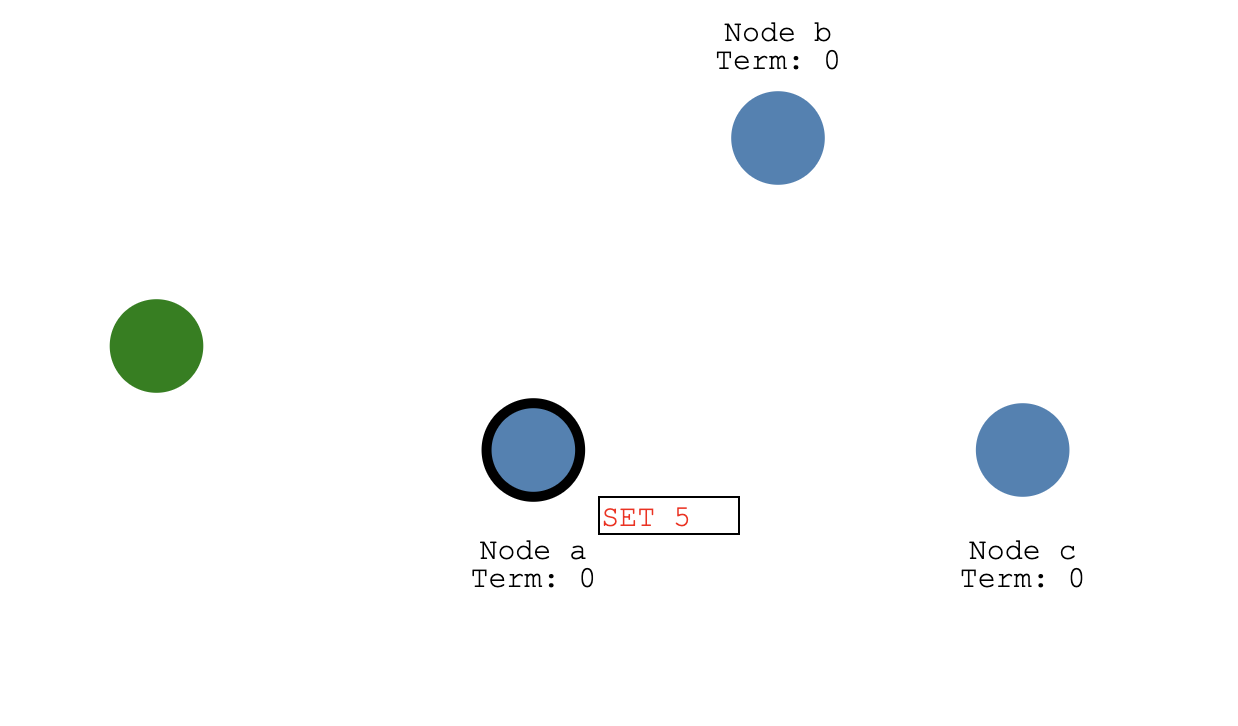
系统刚收到这个设置,它会标记新值,但是还没committed,因为其他节点还没同步这个信息。
Node a就开始向其他节点同步这个设置:
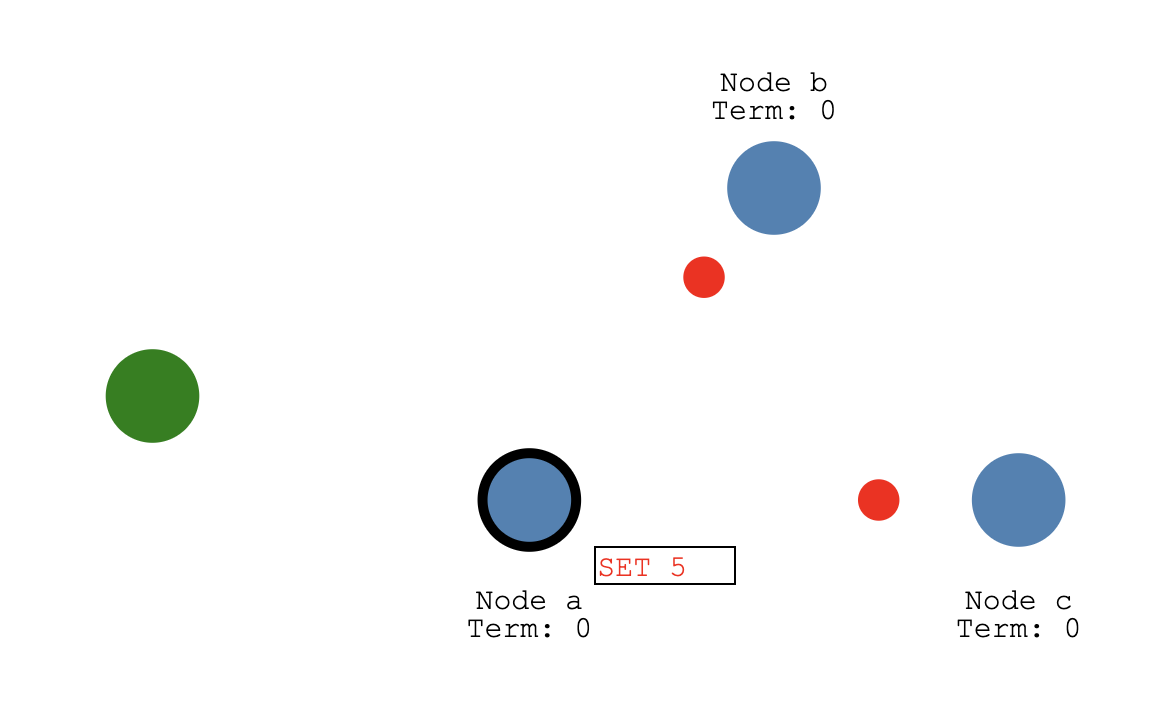
Node b 和Node c确定
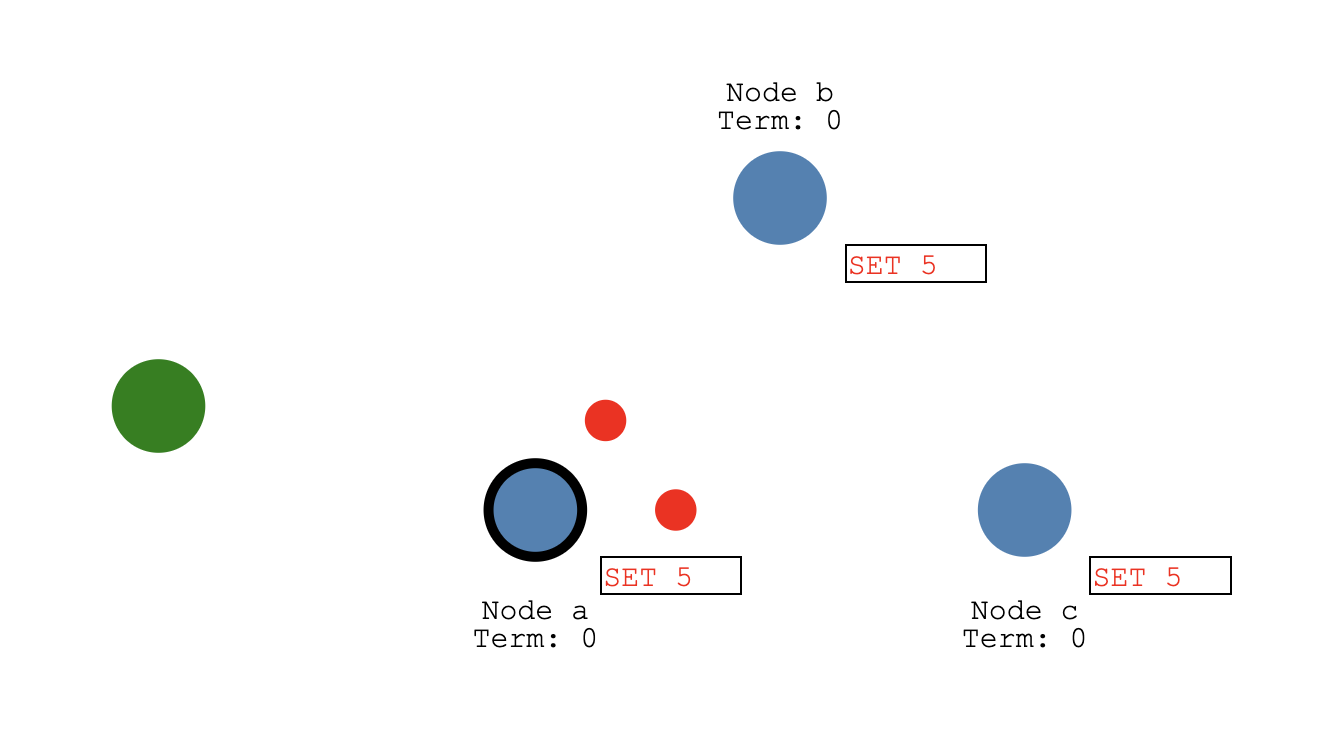
当 follower节点Node b和Node c收到更新并返回确认值(红点就是确认回复)
- Node a commit SET 5(黑框表示已commit)
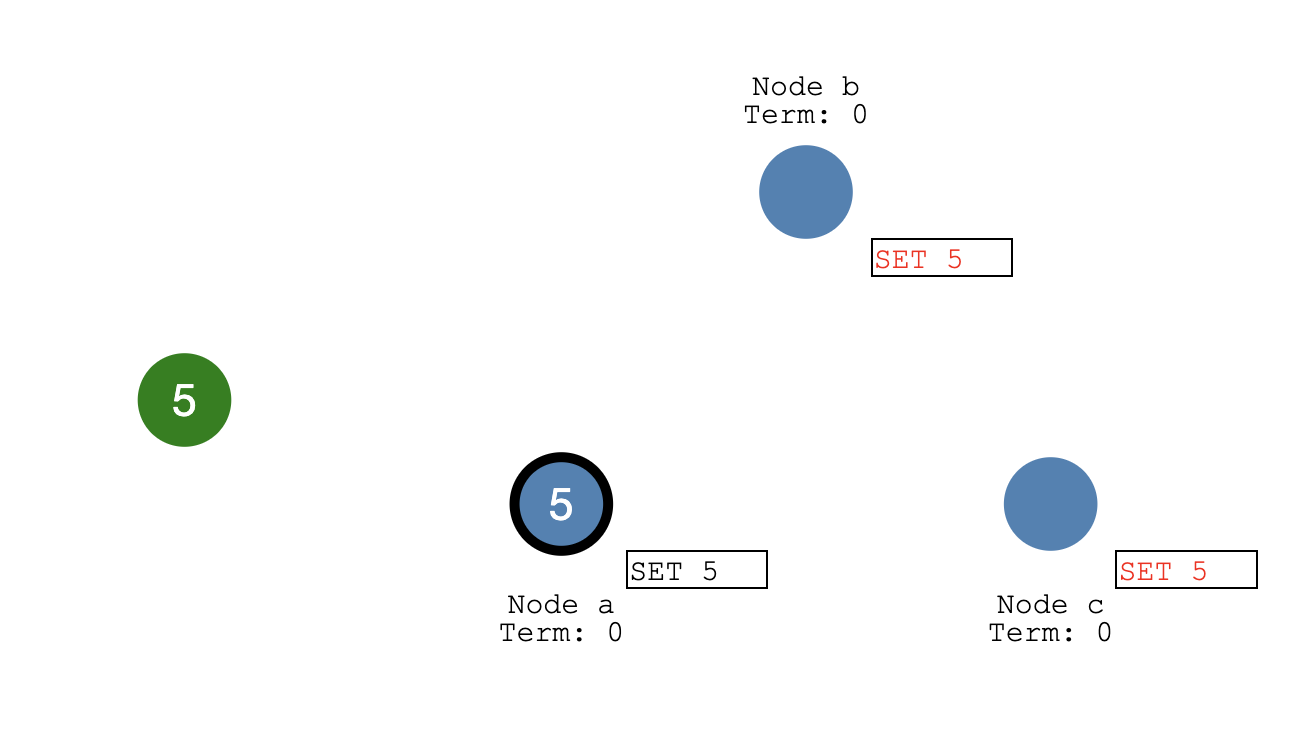
当收到大多数节点的回复,则将这个新值SET 5 正式commit
- commit 信息同步给follower
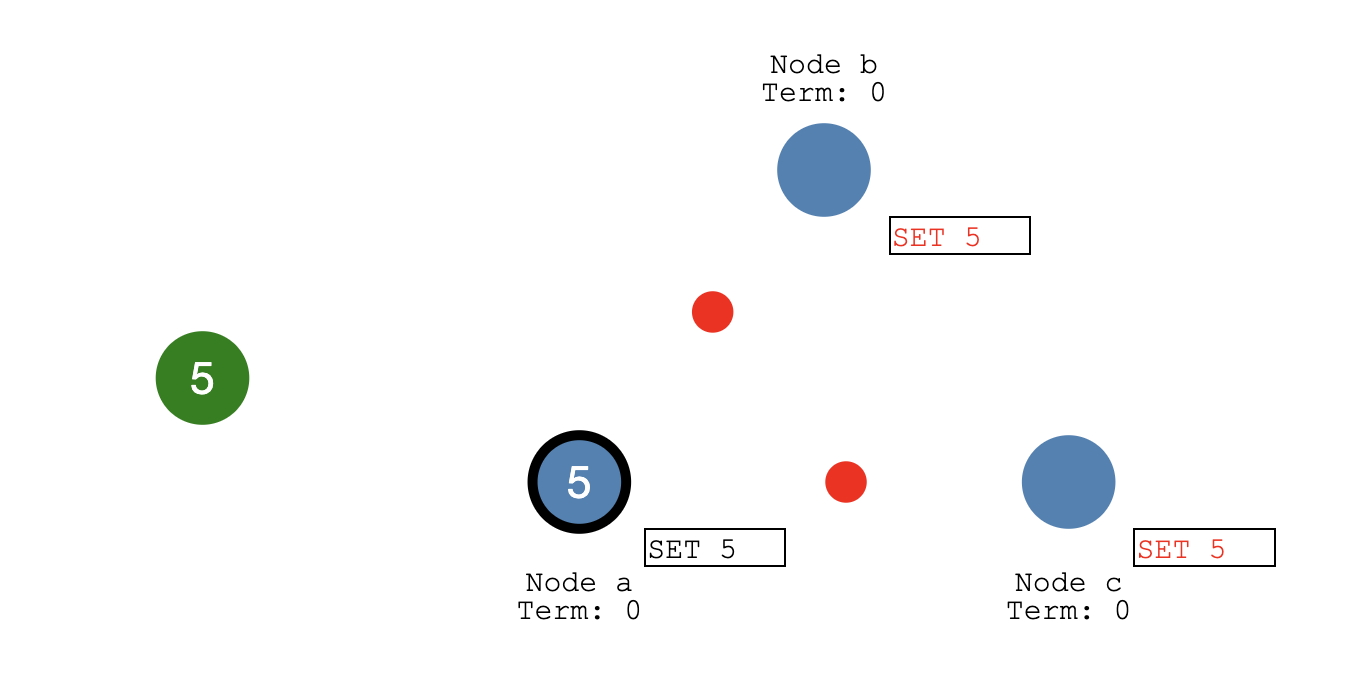
主commit 后会同步到其他节点上也进行commit
- follower 确认更新
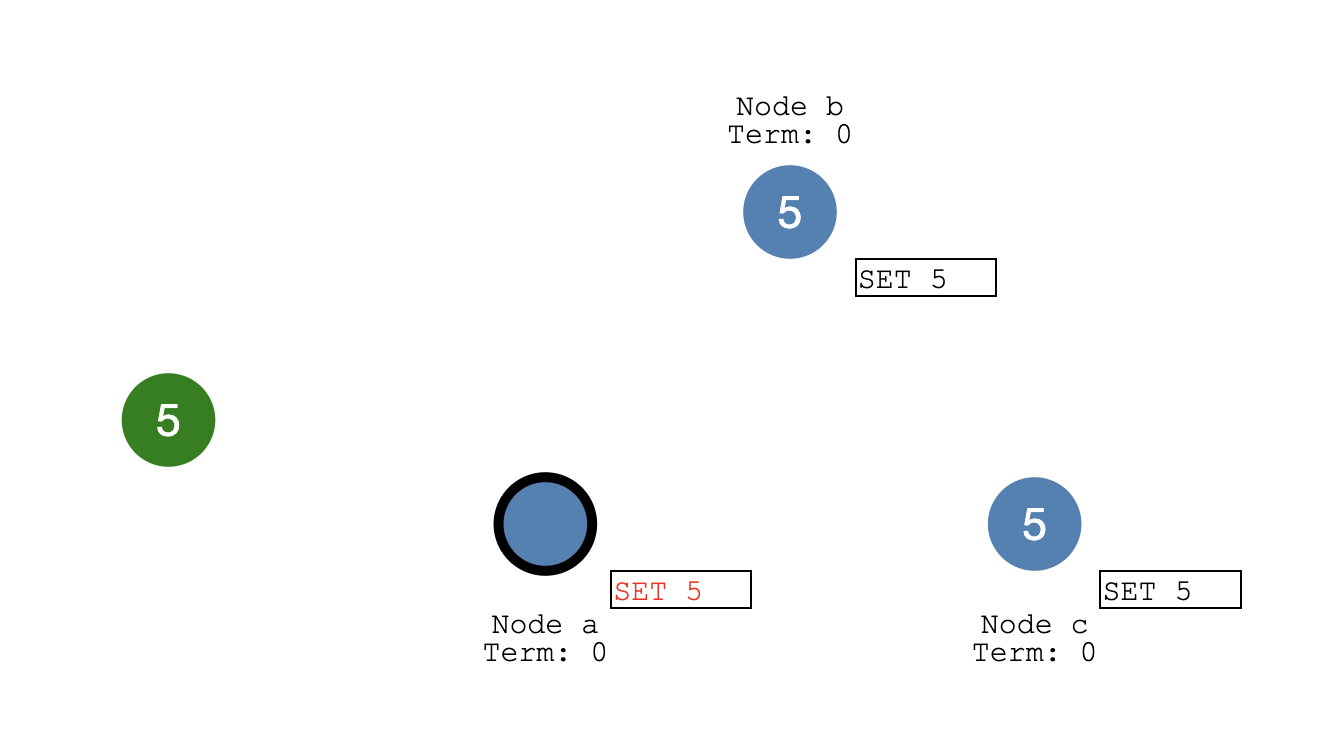
then
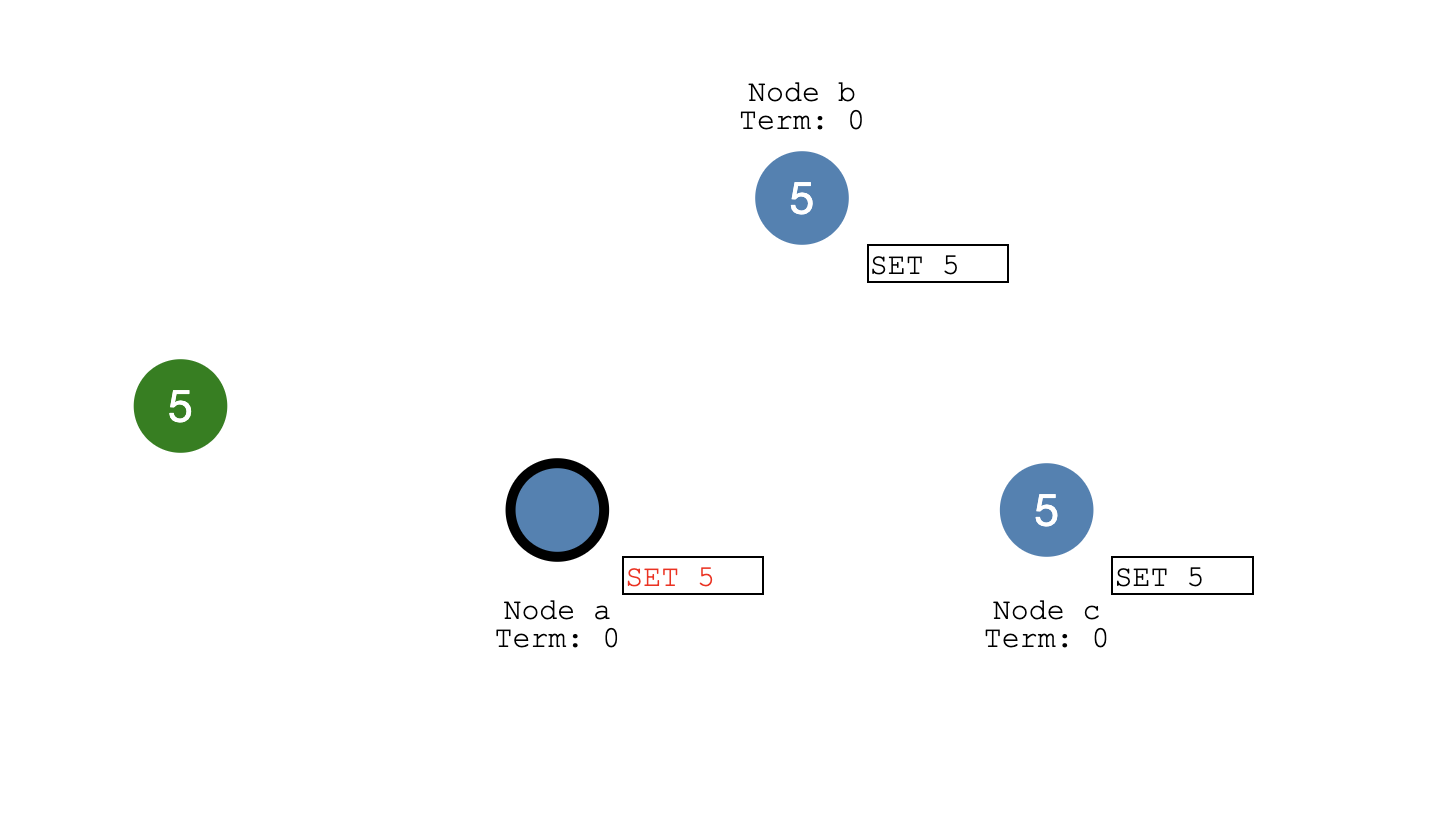
这样就保证了集群数据的a,b,c 节点都一致。 直到这个时候集群这边才会回复response给客户端
防脑裂的几种方式
脑裂在分布式系统中是很常见的情景,通常是由于网络分区导致的节点孤岛,如果不正确处理的话会有数据一致性的问题。有很多种方式去预防它,常见的大致有下面这些:
多数投票
多数投票其实还分为了三种场景,分别如下:
PAXOS和RAFT类的算法,排除对提议版本等的判断,实质上还是多数对少数的投票问题。系统认为占多数的投票结果为正确投票,然后所有节点应用结果。从原理上也可以看出,这种方式最好还是要求奇数节点,当节点为偶数时,当一半节点无法访问时整个系统就会出现问题。
为改善↑面这种情况,当节点只有偶数个时,可以为分布式系统引入第三方仲裁节点,称作arbitration。第三方节点可以为共同可见的服务器、另一个集群节点、也可以为本集群的某节点。这样是为了实现将偶数节点变成奇数个。
还有种类似的方式,为不同的节点指定不同的权重值,这样也可以实现避免‘50%:50%’投票
锁仲裁
这种方式也是CTDB所采用的,就是将一把锁放在某处(分布式文件系统或分布式数据库或类似的地方),各个节点去抢占这把锁,抢到的节点成为master,然后周期性的去renew或设置一个lease时间。这样来保持在某个时间点,只要锁能访问且还有节点存活,那么此分布式系统就不会处于脑裂状态。
具体到某个例子,如基于CTDB的文件系统,就有两种方式,一是将锁放在分布式文件系统上,例如glusterfs,master就在指定目录创建一个文件,然后去renew它;二是某些文件共享因为没有分布式文件系统架构支持,所以利用CTDB自带的ctdb_mutex_ceph_rados_lock_helper,将锁放在了rados里,master会调用rados的接口去检查、设置、租约、并续租这把锁,从而实现防脑裂及recmaster的选举。
图解Raft算法选举
简单概括:
Raft采用的的是投票机制,取得集群多数票的则作为leader。说到leader,其实还应该包括另外的两种状态,candidate和follower。
leader会向集群内的follower发送同步请求,就像是心跳❤️同步,确认节点存活状态。通常在集群初始化的时候,每个节点上都有个状态机,并设置了一个election timeout值。如果在timeout期间没有收到leader发送的同步心跳请求,那么它就认为它的老大已经领便当,并给集群所有节点发起重新选举的信号,鸡贼的是,它默认给自己先投一票(这也是为什么只有两个节点的时候,互相都只认自己的那一票而导致无法成功选举)。在发起选举之后它的状态就会变成candidate,如果其他follower也给他投票,并且最终投票数是大于一半以上,则认为选举成功,成功成为新的leader。同样的在他成为集群新的leader之后,它也要定期给每个节点发送心跳以及和其他follower同步数据。
假设集群中有五个节点,如下所示:
stage0 无主阶段

可以看到每个节点上的timeout并不一样,有的快有的慢,这里节点S2 的时间马上到了,一旦时间到了,且还没有leader同步消息,他就会触发一个投票选举的过程。
stage1 够钟投票

一旦他的timeout到了,那个节点就会认为集群leader死了或者还没初始化,于是就开始发起投票,如图所示,S2先发起了一轮投票,而且都默认给自己投了一票。然后把投票请求发给集群其他节点。
stage 2 返回投票结果

幸运的是此时没有其他节点发起投票,所有很顺利地避免冲突投票的情况,此时集群每个节点都投给S2赞成票

此时S2以及拿到3+票,作为candidate的S2如无意外即将成为集群的leader。
新官上任,开始同步信息

S2 以及顺利当上了集群leader,开始向其他节点发送同步和心跳请求。
同样的,在节点S1,S3,S4,S5的timeout周期内如果没收到leader S2的心跳,它们都会~~~造反~~~重新发起投票,并默认给自己一票。
Leader不可用
这里我把S2关机了试下会怎样。

此时其他节点都收不到S2的心跳了,心中都在默念自己的计时器。
即将发起下一轮投票。。
同时两个candidate

鉴于S2已经没有回应,因此各个节点都还是进入倒计时,此时出现S3会S5差不多同时投票的情况(虽然S3早了一点点发出它的投票请求,但是同时S5的timeout也到了而此时没有leader联系它,所以它也不管S3发起的请求,直接也发起一轮投票)
竞赛开始

S1和S4最先收到了S3的投票请求,所以都给S3投了赞成票👍
而S5因为投了自己为leader,收到S3的投票请求后就,说我也是要当leader的人,咱们走着瞧(等下看投票结果),于是给S3投了反对票👎
S2因为已经宕机,所以对于S3和S5发起的投票均无回应
投票仍然在继续

此时S1和S4节点又收到了S5发起的投票请求,然而S5终究是慢了一拍,毕竟S1和S4刚刚给S3投了赞成票,所以这个时候就只好给S5投反对票🙅 至于S3,因为发起投票都时候毛遂自荐,选了自己为leader,所以它收到S5发的投票请求,固然要拒绝❌,因此返回了一个否定票给S5
胜负既定

过了一段时间后,S5都收到了其他节点给它投的票,结果都是否定票,无缘leader 而S3已经稳妥拿到3/5票数,超过一半,因此它认为自己就是新leader,成功晋级。
新生

在S2节点宕机一段时间后,集群处于无leader的状态已经结束。candidateS3状态已经成功更改为leader
并开始向集群其他节点发起同步信息
S5尽管它发起了投票,但是此时只有一票,不敢擅自做主。因此不会把自己当初leader处理。
集群康复

S5此时已经收到新leader S3的同步消息,此时它也不再坚持自己为leader了,它成为follower 继续向S3汇报。 S1和S4正常回复leader S3 ,每次followers收到了leader心跳💗,都重置倒计时,因此此时不需要投票 此时集群所有节点都健康。
如果此时S2节点恢复

如果S2 恢复了,尽管它知道之前之前的leader,但是系统是有记录步进数的,假设它在宕机前是1代,
S3重新当选的时候就变成2代了,因此他们有不同的步进数。
S2恢复后比较下S3步进数,发现自己是1代的,而S3是2代的。于是他就默默放下leader身份,
重新以follower身份服务于集群
较早前 leader 中不一致的日志将被清除,并与现有 leader 中的日志保持一致。
由于演示系统问题,这里没显示步进数,将就着吧🤷♂️
如果只剩下两个节点存活

此时设置S3,S4,S5为离线状态,剩下S1和S2,两者都不能互相决定谁当leader。 于是分别在各自timeout期后发起了投票 由于其他节点离线了,无响应。而S1和S2都默认给自己一票,并否认别人的投票请求。 最终结局就是互相只得一票,的票数没超过50% 此时整个集群就没有了leader。
其实还有其他情况,比如偶数节点等
one more thing 📱
如果出现网络分区,并且各自为政了,数据是怎么处理的。前面我们知道,为了保证数据的一致,每个节点都会和leader进行数据同步,称之为Log Replication
但是,万一出现网络分区,那就可能有两个leader,各自为政,再到后来集群恢复的时候要怎么处理 👀
正常情况

在发生网络分区之前,一切都还好,B是集群的leader,任期term=1
- 网络分区导致出现两种状态

比如连接网络延长过大或者断开了,导致A,B没办法和 C,D,E通信, 此时B仍然是之前的leader身份,但是 C,D,E已经和leader B失联多时,因此他们认为leader已挂,所有重新选举 结果是E也当上了leader,任期term=2
- 同时又有两个客户端访问两个分区进行数据更新

其中一个客户端设置B的值SET 3
理论上要得到集群大多数节点的同步确认才能commit这条请求。因此这时SET 3的状态是uncommitted
- 客户端2继续请求另一个分区

上面有另外一个客户端,向上面的分区(leader E)进行读写 SET 8 的操作
- 多数节点的确认

由于上面的分区E得到了多数节点(2/3)的确认,所以数据写入成功
- 网络恢复

由于节点E是任期term = 2,是新一代的leader,因此原来的Node B不再担任leader角色。而Node E此时是整个集群的leader
接下来leader Node E开始同步心跳,并进行日志复制(确保数据一致)
然后Node B 和Node A因为刚才设置的值SET 3 因为没有得到集群大多数节点的确认(uncommitted),因此在这次的日志复制过程就会进行数据回滚,然后将日志设置和leader B匹配,即SET 8
现在集群的数据就保证了一致了。
关于为什么要舍弃SET 3这条数据,其实还涉及到CAP理论:一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
而作为分布式系统,P是必然的,抛开P那就是谈不上分布式。
如果只考虑P+A(Partition tolerance+Availability )那就是上面例子🌰,分区同时保证可用性,保证同个时间内所有客户端都能访问。
如果是P+C(Partition tolerance + Consistency)那就是不能保证同时可用,只有等到数据一致前提下才能恢复访问。
总结
- 可以看出 Raft 协议都能很好的应对一致性问题,并且很容易理解。
- Raft一共分为三种角色,leader,follower,candidate,字如其名
- 选举倒计时timeout通常是 150ms ~ 300ms 直接的某个随机值
- 集群启动时,没有leader,而是全部初始化为 follower
- 多个leader出现的时候,对比他们的term即任期(上面的步长),新者为leader
- 数据的流向只能从 Leader 节点向 Follower 节点转移
- 数据在大多数节点提交后才commit
强烈建议自己动手玩一玩demo: