Intro
本文介绍基于搜狗的微信公众号定向爬虫,使用C#实现,故取名WeGouSharp。 本文中的项目托管在Github上,你可以戳WeGouSharp获取源码,欢迎点星。 关于微信公共号爬虫的项目网上已经不少,然而基本大多数的都是使用Python实现 这里又为广大微软系同胞创建了这个轮子,使用C#实现的微信爬虫 蓝本为Chyroc/WechatSogou, 在此还请各位大佬指教。
目录
- 项目结构
- 数据结构
- xpath介绍
- 使用HtmlAgilityPack解析网页内容
- 验证码处理以及文件缓存
一、 项目结构
如下图
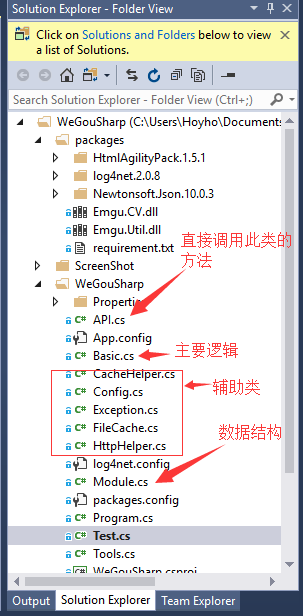
API类:
所有直接的操作封装好在API类中,直接使用里面的方法
Basic类:
主要处理逻辑
FileCache:
主要出现验证码的时候需要使用Ccokie验证身份,此类可以加密后序列化保存UIN,BIZ,COOKIE等内容以供后续使用
HttpHelper类:
网络请求,包括图片
Tools类:
图片处理,cookie加载等
依赖包可以直接使用package文件夹的版本
也可以自行在NuGet添加 如(visual studio-->tools-->Nuget Package Manager-->Package Manager Console):
Install-Package HtmlAgilityPack
二、 数据结构
本项目根据微信公账号以及搜狗搜索定义了多个结构,可以查看模型类,主要包括以下:
公众号结构:
public struct OfficialAccount
{
public string AccountPageurl;
public string WeChatId;
public string Name;
public string Introduction;
public bool IsAuth;
public string QrCode;
public string ProfilePicture;//public string RecentArticleUrl;
}
字段含义
| 字段 1 | 含义 2 |
|---|---|
| AccountPageur | 微信公众号页 |
| WeChatId | 公号ID(唯一) |
| Name | 名称 |
| Introduction | 介绍 |
| IsAuth | 是否官方认证 |
| QrCode | 二维码链接 |
| ProfilePicture | 头像链接 |
公号群发消息结构(含图文推送)
public struct BatchMessage
{
public int Meaasgeid;
public string SendDate;
public string Type; //49:图文,1:文字,3:图片,34:音频,62:视频public string Content;
public string ImageUrl;
public string PlayLength;
public int FileId;
public string AudioSrc;
//for type 图文public string ContentUrl;
public int Main;
public string Title;
public string Digest;
public string SourceUrl;
public string Cover;
public string Author;
public string CopyrightStat;
//for type 视频public string CdnVideoId;
public string Thumb;
public string VideoSrc;
//others
}
字段含义
| 字段 | 含义 |
|---|---|
| Meaasgeid | 消息号 |
| SendDate | 发出时间(unix时间戳) |
| Type | 消息类型:49:图文, 1:文字, 3:图片, 34:音频, 62:视频 |
| Content | 文本内容(针对类型1即文字) |
| ImageUrl | 图片(针对类型3,即图片) |
| PlayLength | 播放长度(针对类型34,即音频,下同) |
| FileId | 音频文件id |
| AudioSrc | 音频源 |
| ContentUrl | 文章来源(针对类型49,即图文,下同) |
| Main | 不明确 |
| Title | 文章标题 |
| Digest | 摘要 |
| SourceUrl | 阅读原文 |
| Cover | 封面图 |
| Author | 作者 |
| CopyrightStat | 可能是否原创 |
| CdnVideoId | 视频id(针对类型62,即视频,下同) |
| Thumb | 视频缩略图 |
| VideoSrc | 视频链接 |
文章结构:
public struct Article
{
public string Url;
public List<string>Imgs;
public string Title;
public string Brief;
public string Time;
public string ArticleListUrl;
public OfficialAccount officialAccount;
}
字段含义
| 字段 | 含义 |
|---|---|
| Url | 文章链接 |
| Imgs | 封面图(可能多个) |
| Title | 文章标题 |
| Brief | 简介 |
| Time | 发表日期(unix时间戳) |
| OfficialAccount | 关联的公众号(信息不全,仅供参考) |
搜索榜结构
public struct HotWord
{
public int Rank;//排行
public string Word;
public string JumpLink; //相关链接
public int HotDegree; //热度
}
三 、xpath介绍
什么是 XPath?
XPath 使用路径表达式在 XML 文档中进行导航 XPath 包含一个标准函数库 XPath 是 XSLT 中的主要元素 XPath 是一个 W3C 标准 简而言之,Xpath是XML元素的位置,下面是W3C教程时间,老鸟直接跳过
XML 实例文档 我们将在下面的例子中使用这个 XML 文档。
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
| 表达 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点 |
| /bookstore | 选取根元素 bookstore 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径 |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置 |
| //@lang | 选取名为 lang 的所有属性 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
###@ 实例 在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
实例
在下面的表格中,列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
来源: http://www.w3school.com.cn/xpath/xpath_syntax.asp
如图,假设我要抓取首页一个banner图,可以在chrome按下F12参考该元素的Xpath,
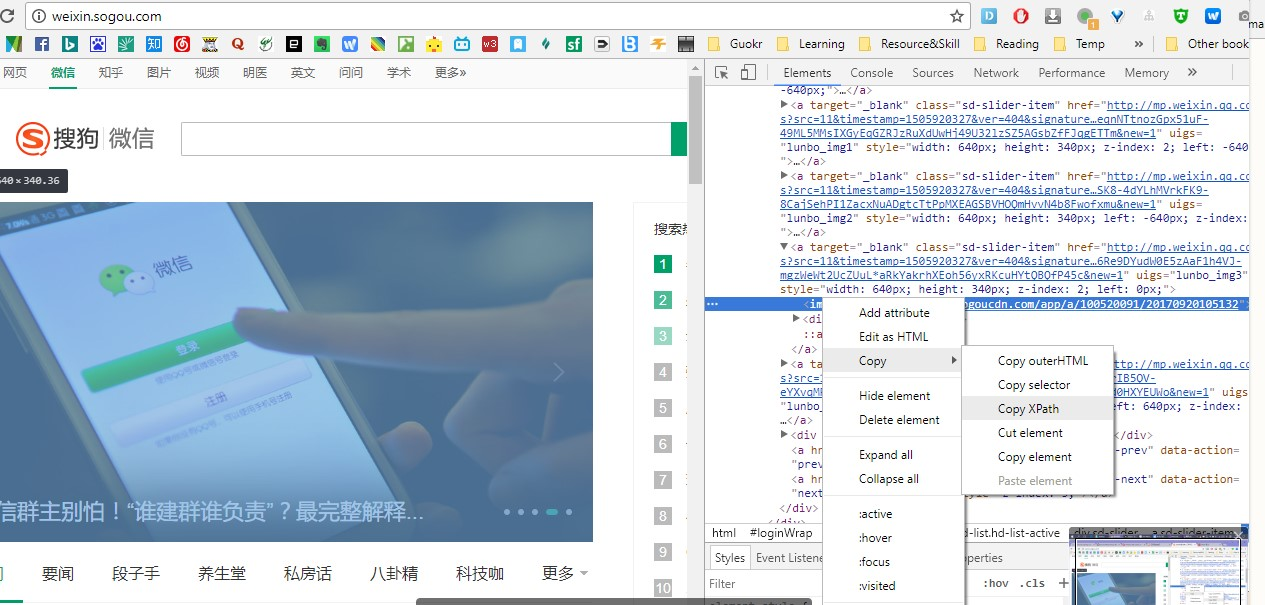
即该图片对应的Xpth为: //*[@id="loginWrap"]/div[4]/div[1]/div[1]/div/a[4]/img
解读:该图片位于ID= loginWrap下面的第4个div下的...的img标签内
为什么这里介绍Xpath,是因为我们网页分析是使用HtmlAgilityPack来解析,他可以把根据Xpath解析我们所需的元素。
比如我们调试确定一个文章页面的特定位置为标题,图片,作者,内容,链接的Xpath即可完全批量化且准确地解析以上信息
四、 使用HtmlAgilityPack解析网页内容
Httptool类里封装了一个较多参数的HTTP GET操作,用于获取搜狗的页面:
因为搜狗本身是做搜索引擎的缘故,所以反爬虫是非常严厉的,因此HTTP GET的方法要注意携带很多参数,且不同页面要求不一样.一般地,要带上默认的referer和host 然后请求头的UserAgent 要伪造,常用的user agent有
public static List<string> _agent = new List<string>
{
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
};
自定义的GET 方法
/// <summary>
/// 指定header参数的HTTP Get方法
/// </summary>
/// <param name="headers"></param>
/// <param name="url"></param>
/// <returns>respondse</returns>
public string Get(WebHeaderCollection headers, string url ,string responseEncoding="UTF-8",bool isUseCookie = false)
{
string responseText = "";
try
{
var request = (HttpWebRequest)WebRequest.Create(url);
request.Method = "GET";
foreach (string key in headers.Keys)
{
switch (key.ToLower())
{
case "user-agent":
request.UserAgent = headers[key];
break;
case "referer":
request.Referer = headers[key];
break;
case "host":
request.Host = headers[key];
break;
case "contenttype":
request.ContentType = headers[key];
break;
case "accept":
request.Accept = headers[key];
break;
default:
break;
}
}
if (string.IsNullOrEmpty(request.Referer))
{
request.Referer = "http://weixin.sogou.com/";
};
if (string.IsNullOrEmpty(request.Host))
{
request.Host = "weixin.sogou.com";
};
if (string.IsNullOrEmpty(request.UserAgent))
{
Random r = new Random();
int index = r.Next(WechatSogouBasic._agent.Count - 1);
request.UserAgent = WechatSogouBasic._agent[index];
}
if (isUseCookie)
{
CookieCollection cc = Tools.LoadCookieFromCache();
request.CookieContainer = new CookieContainer();
request.CookieContainer.Add(cc);
}
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
if (isUseCookie && response.Cookies.Count >0)
{
var cookieCollection = response.Cookies;
WechatCache cache = new WechatCache(Config.CacheDir, 3000);
if (!cache.Add("cookieCollection", cookieCollection, 3000)) { cache.Update("cookieCollection", cookieCollection, 3000); };
}
// Get the stream containing content returned by the server.
Stream dataStream = response.GetResponseStream();
//如果response是图片,则返回以base64方式返回图片内容,否则返回html内容
if (response.Headers.Get("Content-Type") == "image/jpeg" || response.Headers.Get("Content-Type") == "image/jpg")
{
Image img = Image.FromStream(dataStream, true);
using (MemoryStream ms = new MemoryStream())
{
// Convert Image to byte[]
//img.Save("myfile.jpg");
img.Save(ms,System.Drawing.Imaging.ImageFormat.Jpeg);
byte[] imageBytes = ms.ToArray();
// Convert byte[] to Base64 String
string base64String = Convert.ToBase64String(imageBytes);
responseText = base64String;
}
}
else //read response string
{
// Open the stream using a StreamReader for easy access.
Encoding encoding;
switch (responseEncoding.ToLower())
{
case "utf-8":
encoding = Encoding.UTF8;
break;
case "unicode":
encoding = Encoding.Unicode;
break;
case "ascii":
encoding = Encoding.ASCII;
break;
default:
encoding = Encoding.Default;
break;
}
StreamReader reader = new StreamReader(dataStream, encoding);//System.Text.Encoding.Default
// Read the content.
if (response.StatusCode == HttpStatusCode.OK)
{
responseText = reader.ReadToEnd();
if (responseText.Contains("用户您好,您的访问过于频繁,为确认本次访问为正常用户行为,需要您协助验证"))
{
_vcode_url = url;
throw new Exception("weixin.sogou.com verification code");
}
}
else
{
logger.Error("requests status_code error" + response.StatusCode);
throw new Exception("requests status_code error");
}
reader.Close();
}
dataStream.Close();
response.Close();
}
catch (Exception e)
{
logger.Error(e);
}
return responseText;
}
前面关于Xpath废话太多,直接上一个实例,解析公众号页面:
public List<OfficialAccount> SearchOfficialAccount(string keyword, int page = 1)
{
List<OfficialAccount> accountList = new List<OfficialAccount>();
string text = this._SearchAccount_Html(keyword, page);//返回了一个搜索页面的html代码
HtmlDocument pageDoc = new HtmlDocument();
pageDoc.LoadHtml(text);
HtmlNodeCollection targetArea = pageDoc.DocumentNode.SelectNodes("//ul[@class='news-list2']/li");
if (targetArea != null)
{
foreach (HtmlNode node in targetArea)
{
try
{
OfficialAccount accountInfo = new OfficialAccount();
//链接中包含了& html编码符,要用htmdecode,不是urldecode
accountInfo.AccountPageurl = WebUtility.HtmlDecode(node.SelectSingleNode("div/div[@class='img-box']/a").GetAttributeValue("href", ""));
//accountInfo.ProfilePicture = node.SelectSingleNode("div/div[1]/a/img").InnerHtml;
accountInfo.ProfilePicture = WebUtility.HtmlDecode(node.SelectSingleNode("div/div[@class='img-box']/a/img").GetAttributeValue("src", ""));
accountInfo.Name = node.SelectSingleNode("div/div[2]/p[1]").InnerText.Trim().Replace("<!--red_beg-->", "").Replace("<!--red_end-->", "");
accountInfo.WeChatId = node.SelectSingleNode("div/div[2]/p[2]/label").InnerText.Trim();
accountInfo.QrCode = WebUtility.HtmlDecode(node.SelectSingleNode("div/div[3]/span/img").GetAttributeValue("src", ""));
accountInfo.Introduction = node.SelectSingleNode("dl[1]/dd").InnerText.Trim().Replace("<!--red_beg-->","").Replace("<!--red_end-->", "");
//早期的账号认证和后期的认证显示不一样?,对比 bitsea 和 NUAA_1952 两个账号
//现在改为包含该script的即认证了
if (node.InnerText.Contains("document.write(authname('2'))"))
{
accountInfo.IsAuth = true;
}
else
{
accountInfo.IsAuth = false;
}
accountList.Add(accountInfo);
}
catch (Exception e)
{
logger.Warn(e);
}
}
}
return accountList;
}
以上,说白了,解析就是Xpath调试,关键是看目标内容是是元素标签内容,还是标签属性, 如果是标签内容即形式为
<h>我是内容</h>
则: node.SelectSingleNode("div/div[2]/p[2]/label").InnerText.Trim();
如果要提取的目标内容是标签属性,如
<a href="/im_target_url.htm" >点击链接</a>
则node.SelectSingleNode("div/div[@class='img-box']/a").GetAttributeValue("href", "")
其他同理
五 、验证码处理以及文件缓存
公众号的主页(示例广州大学公众号https://mp.weixin.qq.com/profile?src=3×tamp=1505923231&ver=1&signature=gWXdb*Jzt1oByDAzW5aTzEWnXo6mkUwg3Ynjm3CYvKV0kdCLxALBR7JJ-EheLBI-v6UcocJqGmPbUY2KMXuSsg==)因为页面是属于微信的,反爬虫非常严格,因此多次刷新容易产生要输入验证码的页面
多次刷新此页面会出现验证码
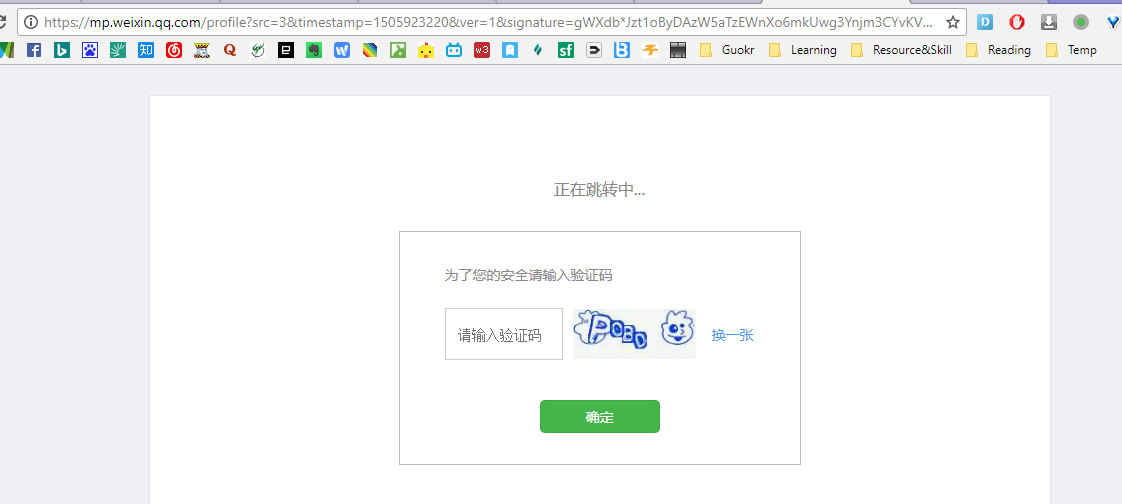
此时要向一个网址post验证码才可以解封
解封操作如下
/// <summary>
/// 页面出现验证码,输入才能继续,此验证依赖cookie, 获取验证码的requset有个cookie,每次不同,需要在post验证码的时候带上
/// </summary>
/// <returns></returns>
public bool VerifyCodeForContinute(string url ,bool isUseOCR)
{
bool isSuccess = false;
logger.Debug("vcode appear, use VerifyCodeForContinute()");
DateTime Epoch = new DateTime(1970, 1, 1,0,0,0,0);
var timeStamp17 = (DateTime.UtcNow - Epoch).TotalMilliseconds.ToString("R"); //get timestamp with 17 bit
string codeurl = "https://mp.weixin.qq.com/mp/verifycode?cert=" + timeStamp17;
WebHeaderCollection headers = new WebHeaderCollection();
var content = this.Get(headers, codeurl,"UTF-8",true);
ShowImageHandle showImageHandle = new ShowImageHandle(DisplayImageFromBase64);
showImageHandle.BeginInvoke(content, null, null);
Console.WriteLine("请输入验证码:");
string verifyCode = Console.ReadLine();
string postURL = "https://mp.weixin.qq.com/mp/verifycode";
timeStamp17 = (DateTime.UtcNow - Epoch).TotalMilliseconds.ToString("R"); //get timestamp with 17 bit
string postData = string.Format("cert={0}&input={1}",timeStamp17,verifyCode );// "{" + string.Format(@"'cert':'{0}','input':'{1}'", timeStamp17, verifyCode) + "}";
headers.Add("Host", "mp.weixin.qq.com");
headers.Add("Referer", url);
string remsg = this.Post(postURL, headers, postData,true);
try
{
JObject jo = JObject.Parse(remsg);//把json字符串转化为json对象
int statusCode = (int)jo.GetValue("ret");
if (statusCode == 0)
{
isSuccess = true;
}
else
{
logger.Error("cannot unblock because " + jo.GetValue("msg"));
var vcodeException = new WechatSogouVcodeException();
vcodeException.MoreInfo = "cannot jiefeng because " + jo.GetValue("msg");
throw vcodeException;
}
}catch(Exception e)
{
logger.Error(e);
}
return isSuccess;
}
解释下: 先访问一个验证码产生页面,带17位时间戳
var timeStamp17 = (DateTime.UtcNow - Epoch).TotalMilliseconds.ToString("R"); //get timestamp with 17 bit
string codeurl = "https://mp.weixin.qq.com/mp/verifycode?cert=" + timeStamp17;
再向这个url query post你的验证码: https://mp.weixin.qq.com/mp/verifycode ?cert=YourTimeStamp17bit&input= YourverifyCode
此处一个大坑,由于HttpWebRequest 默认是不带cookie也不产生的,而这样的严重是依赖cookie ,产生验证码的页面会生成一个cookie,每次不同,post验证码的时候要带上这cookie, 因此这里记得要启用HttpWebRequest cookie 如果启用了cookie,会通过FileCache类将cookie保存在缓存文件,下次请求如果开启cookie container的话就会带上此cookie
CookieCollection cc = Tools.LoadCookieFromCache();
request.CookieContainer = new CookieContainer();
request.CookieContainer.Add(cc);
六、后话
上面只是一部分,刚开始写的时候也没想到会有这么多坑,但是没办法,坑再多只能自己慢慢填了,比如OCR,第三方打码接入,多线程等等后期再实现。一个人的精力毕竟有限,相对满大街的Python爬虫,C#的爬虫性质的项目本来就不多,尽管代码写得非常粗糙,但是我选择了开放源码希望更多人参与,欢迎各位看官收藏,可以的话给个星或者提交代码